Load StackOverflow's StackExchange data in Postgresql®
ftisiot
- 7 minutes read - 1298 wordsHow to load StackOverflow StackExchange data in a PostgreSQL® database!
I recently found about the StackOverflow dataset in Kaggle, which points to the StackExchange link to download the entire data. In this blog I’ll show a (maybe not 100% polished) way to upload the data to several tables in a PostgreSQL database!

The data is provided by the Stack Exchange Network
Create a PostgreSQL database
You can create one with Aiven or just have one local, the below code works in both examples.
Create database tables
Every downloaded file, referring to a specific site, contains the following files:
PostsUsersVotesCommentsPostHistoryPostLinks
The detailed schema information is available in this meta post.
We’ll load the data in a two step approach:
- First load the XML files in a temporary table
- Then load the data from the temporary table into the proper tables with optimised column types

To load the data we need the following data structures:
- a table
data_loadcontaining a uniquedataTEXTcolumn we’ll use to load the XML data row by row - a set of tables matching the file structures in
Posts,Users,Votes,Comments,PostHistory,PostLinks
We can create the data_load table with:
CREATE TABLE data_load (
data text
);
The data_load table will be used to load the XML files on the database and then parse them accordingly.
The following tables are needed to properly store the data in the database.
CREATE TABLE users(
id int PRIMARY KEY,
reputation int,
CreationDate text,
DisplayName text,
LastAccessDate timestamp,
Location text,
AboutMe text,
views int,
UpVotes int,
DownVotes int,
AccountId int
);
CREATE TABLE posts (
id int PRIMARY KEY,
PostTypeId int,
CreationDate timestamp,
score int,
viewcount int,
body text,
OwnerUserId int,
LastActivityDate text,
Title text,
Tags text,
AnswerCount int,
CommentCount int,
ContentLicense text
);
CREATE TABLE badges (
id int PRIMARY KEY,
userId int,
Name text,
dt timestamp,
class int,
tagbased boolean
);
CREATE TABLE comments (
id int,
postId int,
score int,
text text,
creationdate timestamp,
userid int,
contentlicense text
);
CREATE TABLE posthistory (
id int,
PostHistoryTypeId int,
postId int,
RevisionGUID text,
CreationDate timestamp,
userID int,
text text,
ContentLicense text
);
CREATE TABLE postlinks (
id int,
creationdate timestamp,
postId int,
relatedPostId int,
LinkTypeId int
);
CREATE TABLE tags (
id int,
tagname text,
count int,
ExcerptPostId int,
WikiPostId int,
IsRequired boolean,
IsModeratorOnly boolean
);
CREATE TABLE votes(
id int,
postid int,
votetypeid int,
creationdate timestamp
);
Load the data
Let’s download the ai.stackexchange.com the section from StackExchange dedicated to AI. Within the downloaded folder we can find 8 files (1-1 with our tables). Let’s try to load the Users.xml first.
As mentioned before, we’ll perform a two step loading approach:
- Load the XML into a table, with each XML row on a different database row
- Parse the XML to populate the proper tables and columns
The two step approach is needed since the original dataset threats all columns, including ids, as strings. We could either define all the Ids as strings or, do a bit more work to load the data into the proper column definitions.
Step 1: Load the User XML into the data_load table
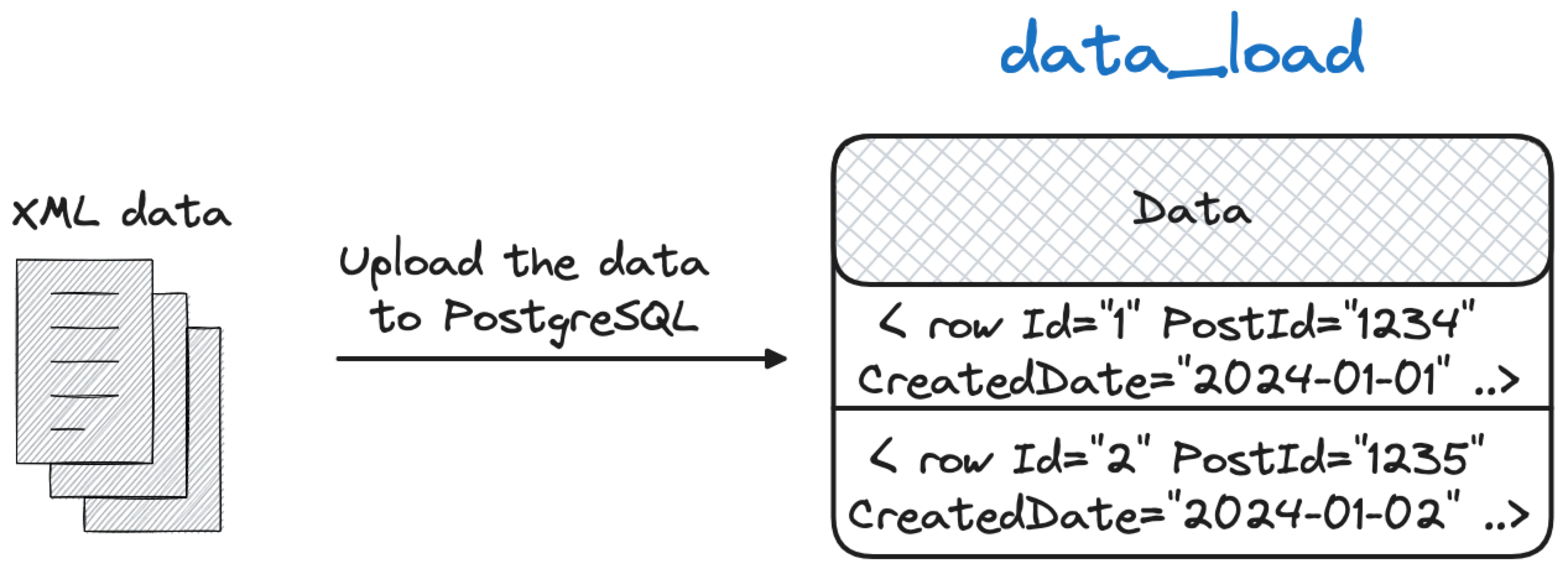
To load the entire XML of the Users.xml file into a temporary data_load table we can connect to the database using psql from the same folder where the Users.xml is located and execute:
\copy data_load from program 'tr -d "\t" < Users.xml | sed -e ''s/\\/\\\\/g''' HEADER
The \copy command allows us to load the dataset into the data_load table. However we need to perform a couple of tricks in order to load it properly:
tr -d "\t" < Users.xmlremoves the tabs from the file.sed -e ''s/\\/\\\\/g''properly escapes the\in the strings.HEADERavoids to load the initial<?xml version="1.0" encoding="utf-8"?>row, unnecessary for our parsing
Step 2: Load the data into the Users table
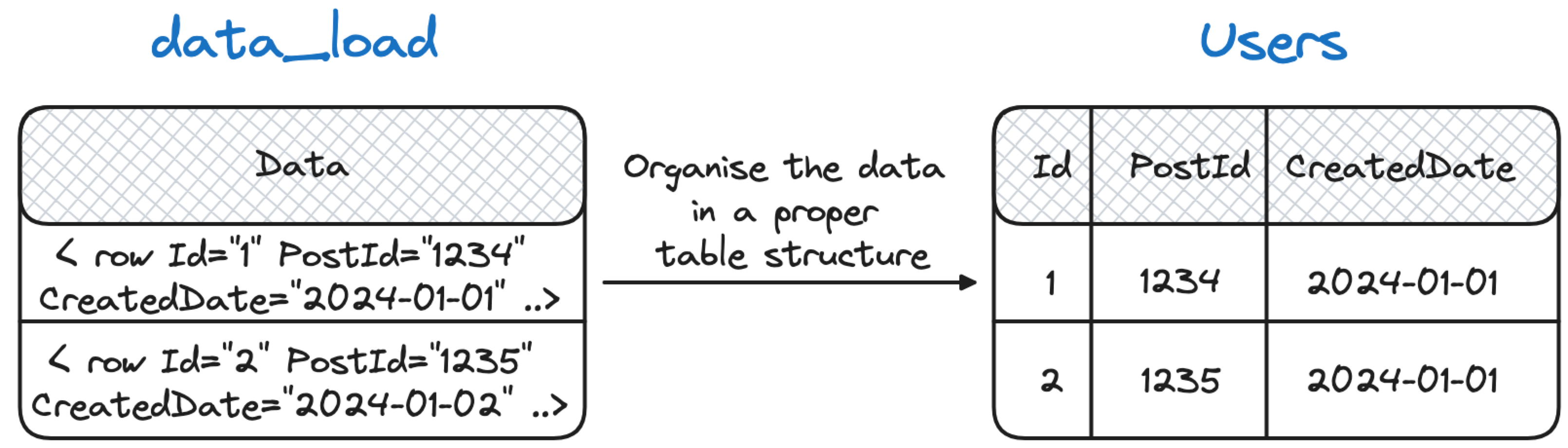
The above command loads the data into the data_load table with one row in the table for each row in the original file. This is not optimal but avoids having to deal with very large files included in just a single blob.
We can make use the fact that each user is contained in a <raw> tag to leverage PostgreSQL ability to parse XML fields with the following:
INSERT INTO USERS (
Id, CreationDate, DisplayName, LastAccessDate, Location,
AboutMe, Views, UpVotes, DownVotes,AccountId, Reputation)
SELECT
(xpath('//@Id', x))[1]::text::int AS id
,(xpath('//@CreationDate', x))[1]::text::timestamp AS CreationDate
,(xpath('//@DisplayName', x))[1]::text AS DisplayName
,(xpath('//@LastAccessDate', x))[1]::text::timestamp AS LastAccessDate
,(xpath('//@Location', x))[1]::text AS Location
,(xpath('//@AboutMe', x))[1]::text AS AboutMe
,(xpath('//@Views', x))[1]::text::int AS Views
,(xpath('//@UpVotes', x))[1]::text::int AS UpVotes
,(xpath('//@DownVotes', x))[1]::text::int AS DownVotes
,(xpath('//@AccountId', x))[1]::text::int AS AccountId
,(xpath('//@Reputation', x))[1]::text::int AS Reputation
FROM data_load, unnest(xpath('//row', data::xml)) x
WHERE regexp_like(data,'[ ]+\<row');
The above uses:
- the
xpathto extract the relevant fields from each user - the
::text::intto cast the extracted field to the proper column type - the filter
regexp_like(data,'[ ]+\<row')to remove the other unnecessary rows, including for example,<users>or</users>
Load the other tables
Similar to the example with Users.xml above, we can load the other tables with the following steps (please not we are truncating the data_load table before loading the next file):
-- Loading posts
truncate data_load;
\copy data_load from program 'tr -d "\t" < Posts.xml | sed -e ''s/\\/\\\\/g''' HEADER
INSERT INTO POSTS (
Id, PostTypeId, CreationDate, score, viewcount,
body, OwnerUserId, LastActivityDate, Title, Tags, AnswerCount,
CommentCount, ContentLicense)
SELECT
(xpath('//@Id', x))[1]::text::int
,(xpath('//@PostTypeId', x))[1]::text::int
,(xpath('//@CreationDate', x))[1]::text::timestamp
,(xpath('//@Score', x))[1]::text::int
,(xpath('//@ViewCount', x))[1]::text::int
,(xpath('//@Body', x))[1]::text
,(xpath('//@OwnerUserId', x))[1]::text::int
,(xpath('//@LastActivityDate', x))[1]::text::timestamp
,(xpath('//@Title', x))[1]::text
,(xpath('//@Tags', x))[1]::text
,(xpath('//@AnswerCount', x))[1]::text::int
,(xpath('//@CommentCount', x))[1]::text::int
,(xpath('//@ContentLicense', x))[1]::text
FROM data_load, unnest(xpath('//row', data::xml)) x
WHERE regexp_like(data,'[ ]+\<row');
-- Loading badges
truncate data_load;
\copy data_load from program 'tr -d "\t" < Badges.xml | sed -e ''s/\\/\\\\/g''' HEADER
INSERT INTO BADGES (
Id, userId, Name, dt, class,
tagbased)
SELECT
(xpath('//@Id', x))[1]::text::int
,(xpath('//@UserId', x))[1]::text::int
,(xpath('//@Name', x))[1]::text
,(xpath('//@Date', x))[1]::text::timestamp
,(xpath('//@Class', x))[1]::text::int
,(xpath('//@TagBased', x))[1]::text::boolean
FROM data_load, unnest(xpath('//row', data::xml)) x
WHERE regexp_like(data,'[ ]+\<row');
-- Loading comments
truncate data_load;
\copy data_load from program 'tr -d "\t" < Comments.xml | sed -e ''s/\\/\\\\/g''' HEADER
INSERT INTO COMMENTS (
Id, postId, score, text, creationdate,
userid, contentlicense)
SELECT
(xpath('//@Id', x))[1]::text::int
,(xpath('//@PostId', x))[1]::text::int
,(xpath('//@Score', x))[1]::text::int
,(xpath('//@Text', x))[1]::text
,(xpath('//@CreationDate', x))[1]::text::timestamp
,(xpath('//@UserId', x))[1]::text::int
,(xpath('//@ContentLicense', x))[1]::text
FROM data_load, unnest(xpath('//row', data::xml)) x
WHERE regexp_like(data,'[ ]+\<row');
-- Loading posthistory
truncate data_load;
\copy data_load from program 'tr -d "\t" < PostHistory.xml | sed -e ''s/\\/\\\\/g''' HEADER
INSERT INTO posthistory (
Id, PostHistoryTypeId, postId, RevisionGUID, CreationDate,
userID, text, ContentLicense)
SELECT
(xpath('//@Id', x))[1]::text::int
,(xpath('//@PostHistoryTypeId', x))[1]::text::int
,(xpath('//@PostId', x))[1]::text::int
,(xpath('//@RevisionGUID', x))[1]::text
,(xpath('//@CreationDate', x))[1]::text::timestamp
,(xpath('//@UserId', x))[1]::text::int
,(xpath('//@Text', x))[1]::text
,(xpath('//@ContentLicense', x))[1]::text
FROM data_load, unnest(xpath('//row', data::xml)) x
WHERE regexp_like(data,'[ ]+\<row');
-- Loading postlinks
truncate data_load;
\copy data_load from program 'tr -d "\t" < PostLinks.xml | sed -e ''s/\\/\\\\/g''' HEADER
INSERT INTO postlinks (
Id, creationdate, postId, relatedPostId, LinkTypeId)
SELECT
(xpath('//@Id', x))[1]::text::int
,(xpath('//@CreationDate', x))[1]::text::timestamp
,(xpath('//@PostId', x))[1]::text::int
,(xpath('//@RelatedPostId', x))[1]::text::int
,(xpath('//@LinkTypeId', x))[1]::text::int
FROM data_load, unnest(xpath('//row', data::xml)) x
WHERE regexp_like(data,'[ ]+\<row');
-- Loading tags
truncate data_load;
\copy data_load from program 'tr -d "\t" < Tags.xml | sed -e ''s/\\/\\\\/g''' HEADER
INSERT INTO tags (
Id, tagname, count, ExcerptPostId, WikiPostId, IsModeratorOnly, IsRequired)
SELECT
(xpath('//@Id', x))[1]::text::int
,(xpath('//@TagName', x))[1]::text
,(xpath('//@Count', x))[1]::text::int
,(xpath('//@ExcerptPostId', x))[1]::text::int
,(xpath('//@WikiPostId', x))[1]::text::int
,(xpath('//@IsModeratorOnly', x))[1]::text::boolean
,(xpath('//@IsRequired', x))[1]::text::boolean
FROM data_load, unnest(xpath('//row', data::xml)) x
WHERE regexp_like(data,'[ ]+\<row');
-- Loading votes
truncate data_load;
\copy data_load from program 'tr -d "\t" < Votes.xml | sed -e ''s/\\/\\\\/g''' HEADER
INSERT INTO votes (
Id, postid, votetypeid, creationdate)
SELECT
(xpath('//@Id', x))[1]::text::int
,(xpath('//@PostId', x))[1]::text::int
,(xpath('//@VoteTypeId', x))[1]::text::int
,(xpath('//@CreationDate', x))[1]::text::timestamp
FROM data_load, unnest(xpath('//row', data::xml)) x
WHERE regexp_like(data,'[ ]+\<row');
Query Time
Once the data is loaded, we can start querying the dataset. For example, finding the top 2 post having a comment with highest score using the following SQL:
SELECT POSTS.Id,
POSTS.Title,
COMMENTS.Text,
COMMENTS.SCORE
FROM
POSTS JOIN COMMENTS ON POSTS.ID = COMMENTS.POSTID
ORDER BY SCORE DESC
LIMIT 2;
Enjoy the dataset and find your own questions and answers!
The following links provide the entire set of DDLs and Loading SQL!